 1874 ' 博客
1874 ' 博客
SpringAI之RAG构建本地知识问答系统(二)
1. 概念
RAG(Retrieval Augmented Generation 检索增强生成)是一种用于将本地数据纳入聊天模型中进行提示,以提升 AI 回答的准确性。例如我们想问一个聊天 模型:张三是谁?由于聊天模型中没有对应的知识,模型就不知道怎么回答我们的问题。RAG技术就可以让我们把张三的个人信息嵌入到上下文中,供聊天模型参考, 这样它就可以回答我们的问题了。通常我们向AI模型中引入私有的数据有三种方式:
- 微调:传统机器学习方法,通过调整模型内部权重来定制模型。这一过程非常复杂且资源消耗极大,并且部分模型不支持微调。
- 提示填充:将私有数据嵌入到提示中,用技术手段在上下文窗口中呈现相关数据。
- 工具调用:注册工具(用户自定义服务),将大语言模型与外部系统 API 连接。下文有详细解释。
RAG用到的就是提示填充,将私有信息嵌入上下文中进行提示,供AI模型参考,并回答相关的问题。如何将本地的私有数据信息,集成到上下文提示中,这就是RAG
解决的问题。下图是RAG实现流程图:
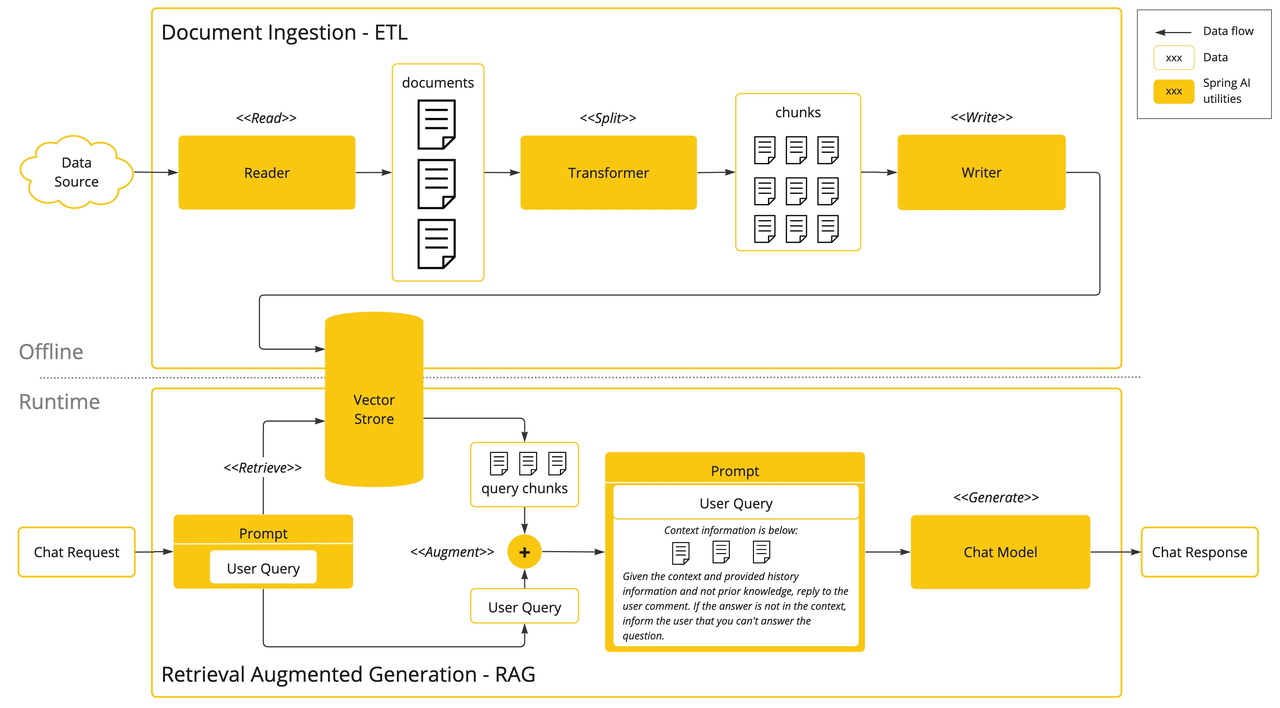
1.1 向量数据库
向量数据库不同于一般的关系型数据库,向量数据库的查询是进行相似性查询,比如我们给定一个查询时,向量数据库会返回与我们查询内容相似的数据。关于这种相 似性的数据计算可以参考向量相似性。
向量数据库用于将你的数据与 AI 模型集成。 使用它们的第一步是将数据加载到向量数据库中。首先要从文档中读取非结构化数据,转换后写入向量数据库。这一流 程就是下面介绍的ETL流程。
Spring AI为我们实现了多种向量数据库支持,详情参见文档。Spring AI 通过 VectorStore 接口提供了与向量数据库交互的API。
批处理策略
我的例子中使用的SimpleVectorStore来作为向量存储库,目前我对这个批处理策略概念认识不深刻,以下是翻译自官方:
嵌入模型将文本作为令牌处理,并且有最大令牌限制,通常称为上下文窗口大小。 这限制了可以在单个嵌入请求中处理的文本量。 尝试在一次调用中嵌入太多令牌 可能会导致错误或截断的嵌入。 为了解决这个令牌限制,Spring AI 实现了批处理策略。
这里提到了嵌入模型,向量数据库中存储数据,就会将文档计算为embedding,它是文本、图像或视频的数值表示,用于捕获输入之间的关系。详情使用说明参考 嵌入模型。
Spring AI 提供了一个名为TokenCountBatchingStrategy的默认实现。 此策略基于文档的令牌计数进行批处理,确保每个批次不超过计算的最大输入令牌
计数。如果要自己定义这个Bean,如下所示:
@Bean
public BatchingStrategy customTokenCountBatchingStrategy() {
return new TokenCountBatchingStrategy(
EncodingType.CL100K_BASE, // 指定编码类型
8000, // 设置最大输入令牌计数
0.1 // 设置保留百分比
);
}
详情信息可以参见官方的批处理策略说明。
1.2 ETL流程
要将文档中的非结构化数据存储到向量数据库中,其实就是一个ETL流程(提取,转换,加载)。如下图所示:
 ETL管道有三个主要组件:
ETL管道有三个主要组件:
- DocumentReader - 实现Supplier<List
> - DocumentTransformer - 实现Function<List
, List > - DocumentWriter - 实现Consumer<List
>
假设我们有以下ETL类型的实例:
- PagePdfDocumentReader - DocumentReader的实现
- TokenTextSplitter - DocumentTransformer的实现
- VectorStore - DocumentWriter的实现
要执行将数据加载到向量数据库的基本操作以用于检索增强生成模式,代码如下:
// 读取,转换,加载
vectorStore.accept(tokenTextSplitter.apply(pdfReader.get()));
2. 搭建系统
我们首先需要引入相关的必要依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Advisor为RAG提供开箱即用支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!-- 支持docx,pdf,html等文档提取 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- ollama 模型依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!-- vaadin前端依赖 -->
<dependency>
<groupId>com.vaadin</groupId>
<artifactId>vaadin-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>in.virit</groupId>
<artifactId>viritin</artifactId>
<version>${viritin.version}</version>
</dependency>
</dependencies>
2.1 创建向量存储
这里使用Spring AI提供的SimpleVectorStore进行测试,该实现也仅用于教育和学习,实际使用请选择其他向量存储库。
@Configuration
public class SimpleVectorStoreConfig {
/**
* 初始化向量数据库,SimpleVectorStore
*
* @param embeddingModel embedding模型
* @return 向量数据库实例
*/
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel)
.batchingStrategy(customBatchingStrategy()).build();
}
/**
* 批处理策略,这里定义该bean后,该自定义的bean将被EmbeddingModel实现自动使用,替换默认的策略
*
* 如果没有定义这个的话,spring自动会配置一个默认构造函数的TokenCountBatchingStrategy对象
*
* @return 批处理策略
*/
public BatchingStrategy customBatchingStrategy() {
// 此 bean 将覆盖默认的 BatchingStrategy
return new TokenCountBatchingStrategy(
EncodingType.CL100K_BASE,
132900, // 比模型的实际限制高得多
0.1);
}
}
2.2 ETL存储向量
我这里使用的是apache tika来进行文档读取,它支持多种文档格式PDF,DOC/DOCS,PPT/PPTX等,将文档中的数据读取为Document元数据,然后将Document进 行转换后存储到向量数据库中。
/**
* <pre>
* RAG数据处理之ETL流程
* 使用apache tika从各种文档中提取文本,将文本提取出Document后,存储到向量数据库
*
* 向量数据库使用参考:<a href="https://doc.spring4all.com/spring-ai/reference/api/vectordbs.html#_%E7%A4%BA%E4%BE%8B%E7%94%A8%E6%B3%95">向量数据库使用说明</a>
* ETL流程参考:<a href="https://doc.spring4all.com/spring-ai/reference/api/etl-pipeline.html#_etl%E6%8E%A5%E5%8F%A3">ETL流程</a>
*
* </pre>
* @author luliangwei
**/
@Component
public class CustomTikaDocumentReader {
/**
* logger
*/
private static final Logger logger = LoggerFactory.getLogger(CustomTikaDocumentReader.class);
/**
*
* 向量数据库api,用于存储从文档中提取的Document
*
*/
@Autowired
private VectorStore vectorStore;
@Value("classpath:/docs/terminal.pdf")
private Resource resource;
/**
* 提取数据
* 使用TikaDocumentReader从文档中提取内容为Document,TikaDocumentReader支持多种文档格式:doc/docx/ppt/pptx/html
*
* @return 提取的文档
*/
public List<Document> loadDocuments() {
TikaDocumentReader reader = new TikaDocumentReader(resource);
return reader.read();
}
/**
* 转换器
* TokenTextSplitter使用CL100K_BASE编码基于标记计数将文本分割成块。帮助文档分割以适应AI模型的上下文窗口
*
* @param documents 从文档中提取的Document
* @return 分割后的Document
*/
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
/**
* 加载数据到VectorStore中
* 对应RAG的ETL流程
*/
@PostConstruct
public void loadDocument2Store() {
// Extract
var docs = this.loadDocuments();
// Transform
var splitDocs = splitDocuments(docs);
logger.info("加载文档中的内容到vector store, 文档数量:{}", splitDocs.size());
// Load
this.vectorStore.add(splitDocs);
}
}
2.3 配置ChatClient
基于ollama构建离线大模型系统,并集成RAG实现本地知识问答系统。Spring AI提供了Advisor API来为常见的RAG提供开箱即用的支持,我这里使用的是
QuestionAnswerAdvisor。同时配置了系统默认的ChatMemory来提供聊天记忆支持。这里我们需要区别了解聊天内存和聊天历史之间的区别很重要。
- 聊天内存:大型语言模型保留并用于在整个对话中保持上下文感知的信息。
- 聊天历史:整个对话历史,包括用户和模型之间交换的所有消息。
ChatMemory旨在管理聊天内存。它允许存储和检索与当前对话上下文相关的消息。但是,它不适合存储聊天历史。
/**
* spring boot自动配置的基于ollama聊天模型
*/
@Autowired
private OllamaChatModel ollamaChatModel;
/**
* spring自动配置的基于内存的聊天记忆
* <p>
* <a href="https://docs.spring.io/spring-ai/reference/api/chat-memory.html">聊天记忆与聊天历史的区别参考文档</a>
*/
@Autowired
private ChatMemory chatMemory;
/**
* 向量存储,已在{@link SimpleVectorStoreConfig}中创建
*/
@Autowired
private VectorStore vectorStore;
@Value("classpath:prompts/system-message.st")
private Resource resource;
@Bean
public ChatClient chatClient() {
return ChatClient.builder(ollamaChatModel)
.defaultSystem("只回答用户问题,不需要解释你如何思考")
.defaultAdvisors(
// 添加默认的聊天记忆Advisor
MessageChatMemoryAdvisor.builder(chatMemory).build(),
// 添加RAG Advisor
QuestionAnswerAdvisor.builder(vectorStore)
.promptTemplate(SystemPromptTemplate.builder().resource(resource).build())
.searchRequest(SearchRequest.builder().similarityThreshold(0.6d).topK(3).build())
.build(),
// 添加日志
new SimpleLoggerAdvisor())
.build();
}
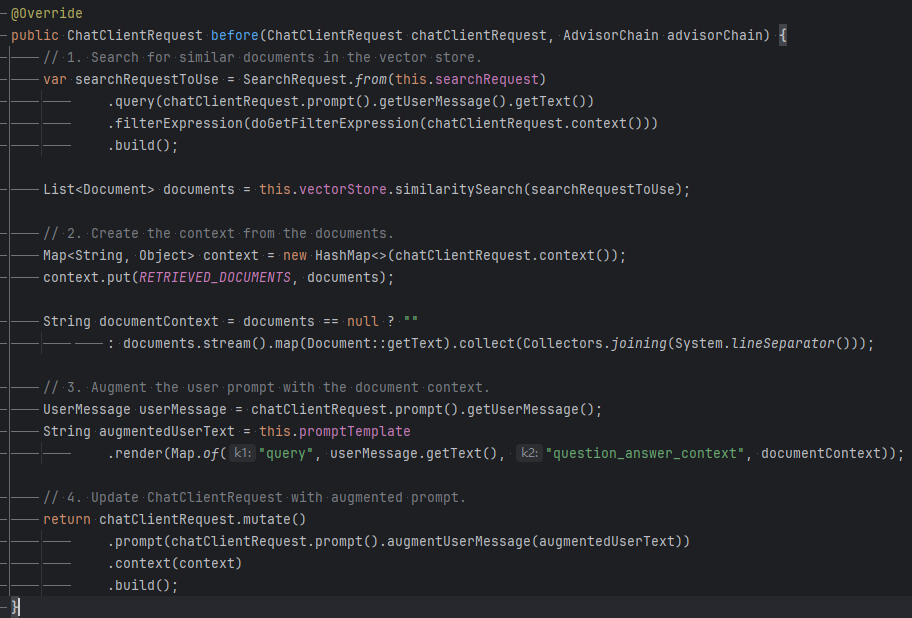
在这个ChatClient配置中,使用了promptTemplate模板来增强用户问题与检索到的文档,对模板有两个要求:
- 一个
query占位符,用于接收用户问题。 - 一个
question_answer_context占位符,用于接收检索到的上下文。
我这里的模板定义如下:
{query}
你是一个信息查询AI助手,你的名字叫小核桃AI。你正在与用户进行自然对话,请根据用户消息,直接进行友好、简洁的回应。
上下文信息如下:
-----------------------------
{question_answer_context}
-----------------------------
通过QuestionAnwserAdvisor源码可以看到,会将用户的问题填充到query,从向量数据库检索到的相似性文档会放到question_answer_context中。关于自
定义模板的使用详细参考官方文档。
2.4 创建聊天对话
经过上面三个步骤,我们实现了如下功能:
- 实例化了一个
VectorStore; - 将pdf文档内容进行提取,转换,并存储到了向量数据库
VectorStore中; - 创建了一个
ChatClient,并配置了聊天记忆和RAG模板;
下面就可以基于ChatClient与大模型进行聊天,并询问一些本地知识库才有数据的相关问题了。这里我的ollama模型使用的是qwen3:14b,嵌入模型使用的是
默认的mxbai-embed-large。application.yaml配置如下:
server:
port: 9102
spring:
ai:
ollama:
base-url: http://192.168.140.7:11434
chat:
options:
model: qwen3:14b
embedding:
model: mxbai-embed-large
logging:
level:
root: debug
logging:
level:
org:
springframework:
ai:
chat:
client:
advisor: DEBUG
聊天代码实现如下:
@Service
public class ChatService {
/**
* logger
*/
private static final Logger logger = LoggerFactory.getLogger(ChatService.class);
@Autowired
private ChatClient chatClient;
@Autowired
private ChatMemory chatMemory;
@Autowired
private VectorStore vectorStore;
/**
* 创建对话的uuid
*
* @return 每个对话唯一的uuid
*/
public String establishChat() {
String conversationId = UUID.randomUUID().toString();
logger.info("establish chat with conversionId: {}", conversationId);
return conversationId;
}
/**
* 开始与AI大模型进行对话聊天
*
* @param message 用户发送的聊天消息
* @param conversationId 对话ID
* @return AI助手的回答内容
*/
public Flux<ChatResponse> chat(String message, String conversationId) {
logger.info("当前聊天记忆中的信息数:{}", chatMemory.get(conversationId).size());
return chatClient.prompt()
.user(message)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId))
.stream()
.chatResponse();
}
}
为了便于聊天,使用vaadin实现了一个简单的聊天界面,关于vaadin的使用参考之前的文章,测试效果如下:
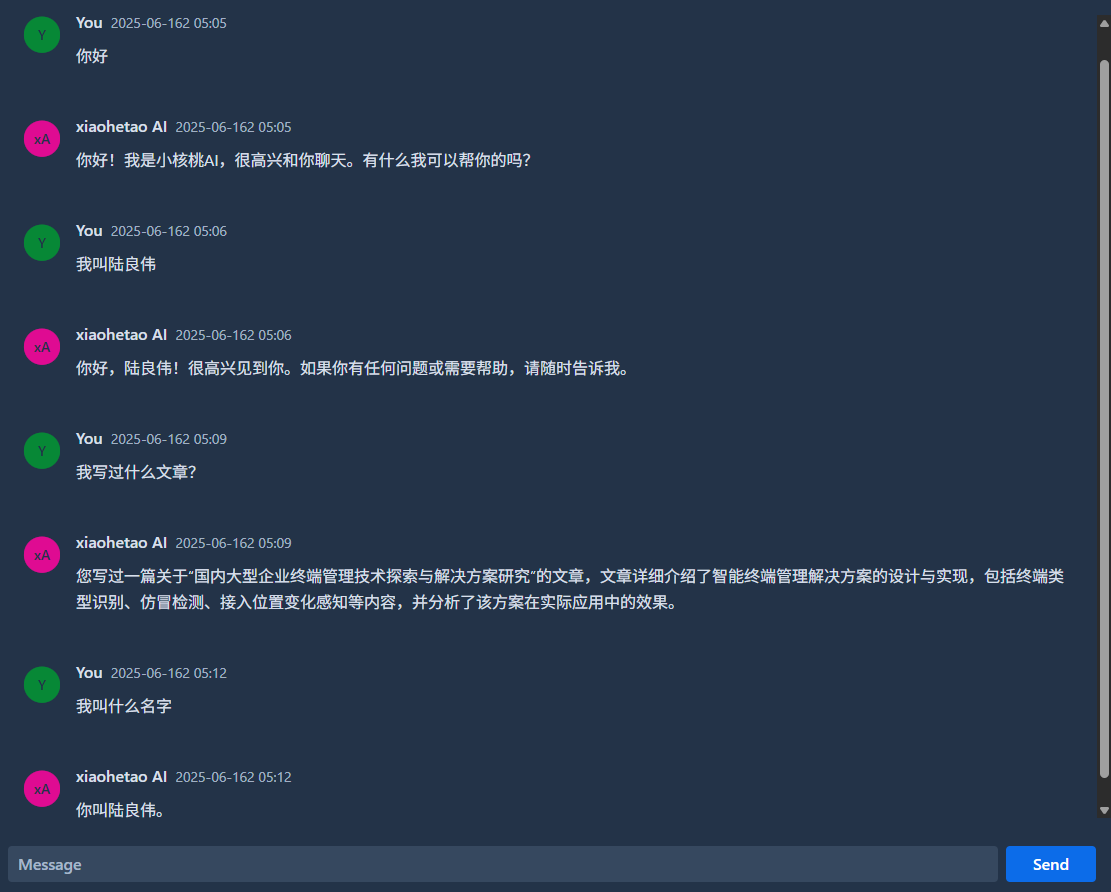 可以看到AI聊天助手已经可以根据上下文记住我的名字,并且可以从本地知识库中回答关于我的文章相关内容。
可以看到AI聊天助手已经可以根据上下文记住我的名字,并且可以从本地知识库中回答关于我的文章相关内容。
3. 遇到的问题
- 模板调整
在实际测试过程中,提示模板需要进行不断调整,才能得到一个相对准确的回答,目标是给AI系统提供准确的提示,才能指导其回复的更准确。 - 聊天记忆
聊天记忆ChatMemory采用默认实现MessageWindowChatMemory,可以指定记忆的上下文对话数量,其内部使用的ChatMemoryRepository是InMemoryChatMemoryRepository,内部使用的是ConcurrentHashMap实现。当我们在ChatClient配置了MessageChatMemoryAdvisor后, 它会自动将聊天对话的用户信息和AI回答的信息存储到内存中,不需要手动显示的添加进去。