1874 ' 博客
1874 ' 博客
基于Ollama部署本地大语言模型
1. 介绍
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。我们安装好Ollama平台后,就可以在 该平台上运行相应的大模型,如:deepseek-r1,gemma3,qiwen等多种大模型,根据需求选中即可,Ollama支持多种大模型,详情可见官网。
2. 安装
Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。Ollama 对硬件要求不高,旨在让用户能够轻松地在本地运行、 管理和与大型语言模型进行交互。
- CPU:多核处理器(推荐 4 核或以上)。
- GPU:如果你计划运行大型模型或进行微调,推荐使用具有较高计算能力的 GPU(如 NVIDIA 的 CUDA 支持)。
- 内存:至少 8GB RAM,运行较大模型时推荐 16GB 或更高。
- 存储:需要足够的硬盘空间来存储预训练模型,通常需要 10GB 至数百 GB 的空间,具体取决于模型的大小。
- 软件要求:确保系统上安装了最新版本的 Python(如果打算使用 Python SDK)。
2.1 docker安装
# 下载最新的docker镜像
docker pull ollama/ollama
# 启动容器
docker run -d -v /root/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
2.2 Linux安装
curl -fsSL https://ollama.com/install.sh | sh
3. 启动大模型
此处启动deepseek-r1:7b模型,参数后面的b表示billion,表示模型的参数量级,直接影响计算复杂度和显存占用。
- DeepSeek 1.5B:15亿参数(小型模型,适合轻量级任务)
- DeepSeek 7B:70亿参数(主流规模,平衡性能与资源)
- DeepSeek 70B:700亿参数(高性能需求场景)
- DeepSeek 671B:6710亿参数(超大规模,对标PaLM/GPT-4)
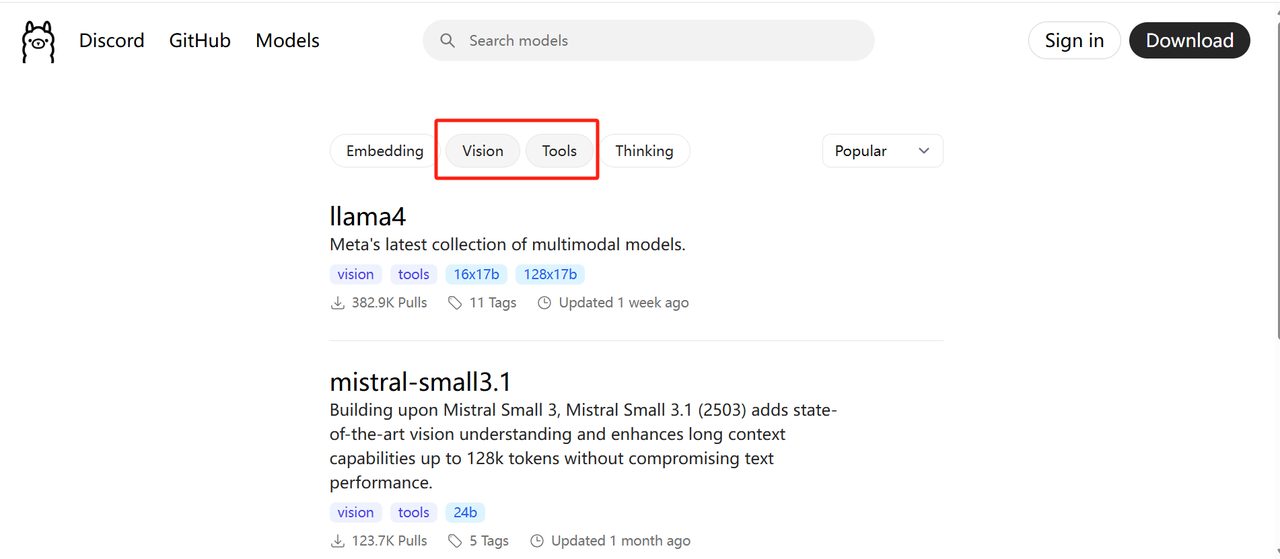
ollama支持多种模型,可参见官网:https://ollama.com/library,可以对需要的模型进行筛选,比如需要支持image输入,和支持工具调用的模型:
# 进入ollama容器
docker exec -it ollama /bin/bash
# 运行deepseek-r1大模型
ollama run deepseek-r1:7b
运行deepseek-r1:7b模型成功后,输出如下,此时我们就可以在命令行进行对话了。
 ollama的其它命令可以使用ollama -h查看:
ollama的其它命令可以使用ollama -h查看:
root@64a95672e27b:/# ollama -h
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
至此我们已经在本地安装了一个deepseek-r1大模型,并且实现了和它的对话。
4. 安装OPEN WebUI
上一章节中用命令行访问大模型不是很友好,我们可以使用Open webUI来访问本地部署的打磨,其界面和chat-gpt类似,支持多种大模型,具体信息见官网。 这里我们使用docker进行快速安装并将open webui连接到ollama实例。 Open webUI官方docker镜像由于国内下载比较慢,可以使用下列命令中的国内镜像,或者 国内仓库拉取指定版本的镜像。
# 拉取镜像
docker pull ghcr.io/open-webui/open-webui:main
# 官方镜像太慢了,换为国内镜像
docker pull ghcr.nju.edu.cn/open-webui/open-webui:main
# 启动镜像并连接到ollama
docker run -d -p 3000:8080 -v /root/open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://192.168.140.7:11434 --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
启动时间比较长,需要耐心等下,当日志出现下列信息后表示启动成功,启动成功后访问http://your-ip:3000/auth即可进行注册并登录。启动open-webui的时
候,如果使用了-v 映射端口,且ollama和open-webui在同一台服务器上时,ollama的url地址不能填写127.0.0.1,需要添加宿主机的IP地址。
 首次登录注册账号后可以看到界面如下:
首次登录注册账号后可以看到界面如下:
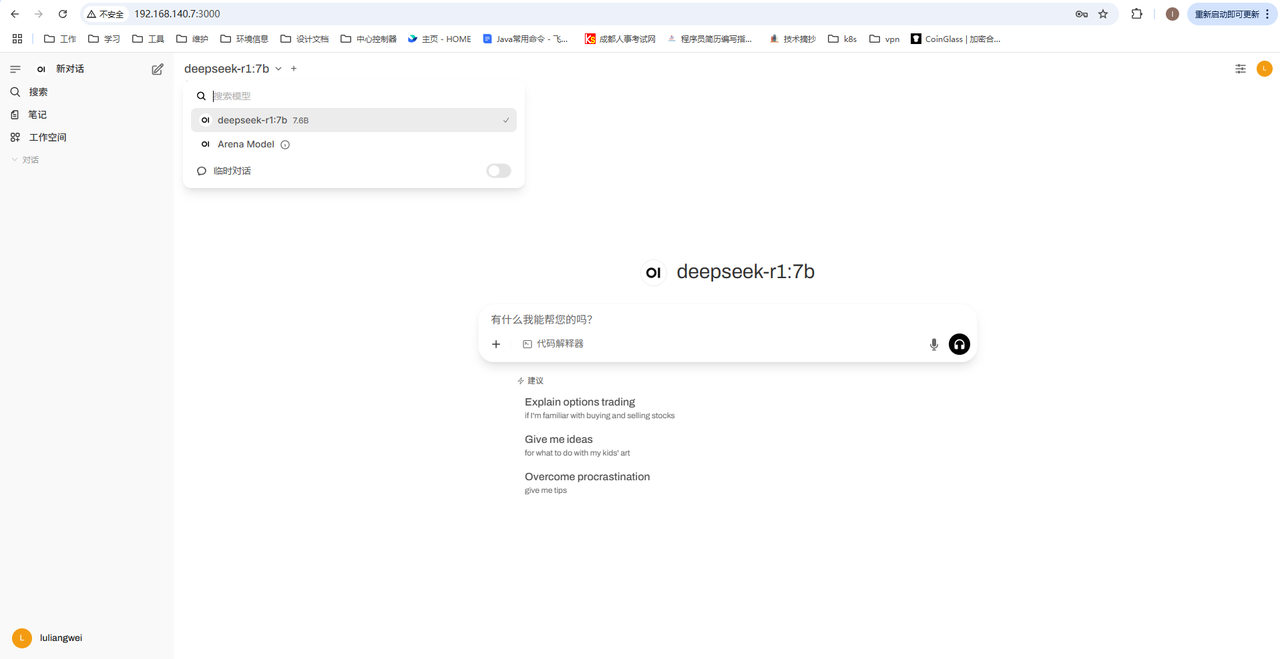 这里可以看到我们本地运行的大模型deepseek-r1:7b,现在就可以通过open-webui进行对话了。
这里可以看到我们本地运行的大模型deepseek-r1:7b,现在就可以通过open-webui进行对话了。
5. ollama拉取模型失败
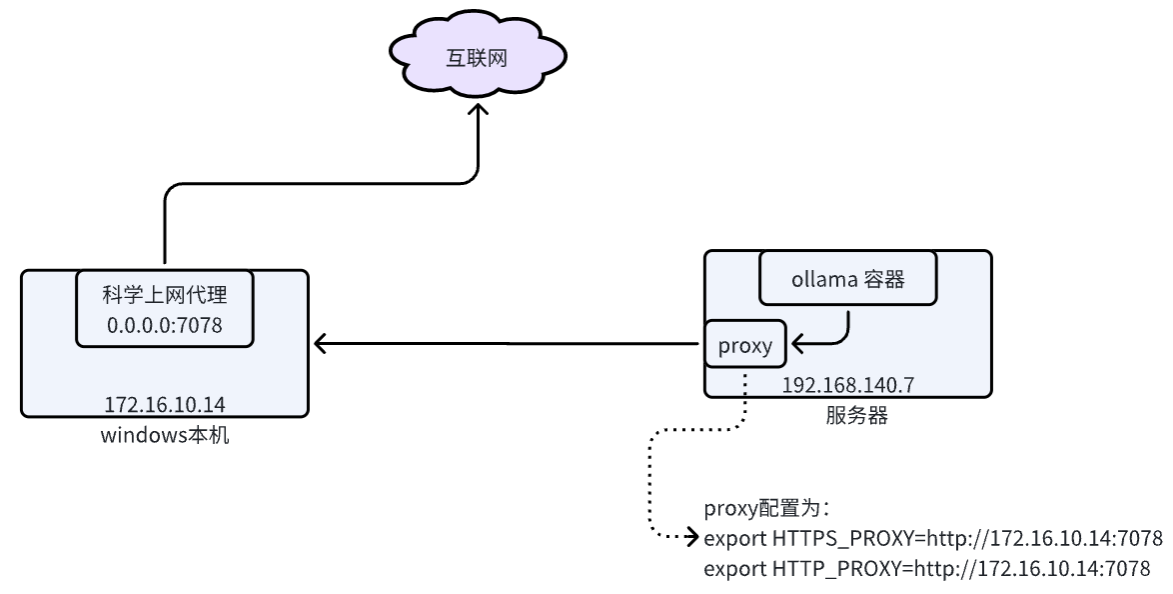
由于网络原因,ollama可能出现在服务器拉取模型失败的情况,此时就需要进行科学上网,然后配置代理再进行拉取模型了,以我自己的环境为例:服务器需要访问我
windows本地的代理,然后通过代理访问外网。
windows本地使用了monocloud科学上网代理,监听端口为7078,通过如下命令在windos powershell中可以看到监听的地址为127.0.0.1,代表只能本地访问 该代理,此时需要将监听地址改为0.0.0.0
PS C:\Users\lenovo> netstat -ano | findstr :7078
TCP 127.0.0.1:7078 0.0.0.0:0 LISTENING 9924
TCP 127.0.0.1:7078 127.0.0.1:50982 ESTABLISHED 9924
TCP 127.0.0.1:7078 127.0.0.1:50996 ESTABLISHED 9924
TCP 127.0.0.1:7078 127.0.0.1:51008 ESTABLISHED 9924
TCP 127.0.0.1:7078 127.0.0.1:54587 ESTABLISHED 9924
将地址改为0.0.0.0,需要先关闭monocloud客户端代理,然后打开ALLOW Lan配置。
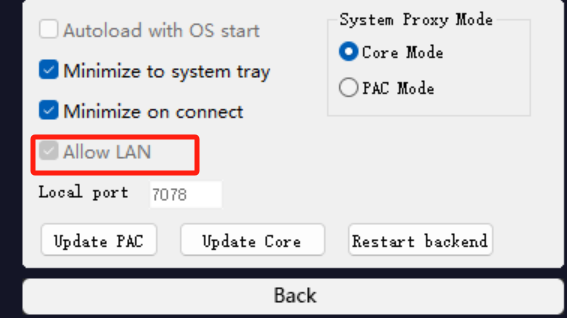 此时再执行上面的命令就可以看到已经监听0.0.0.0地址了
此时再执行上面的命令就可以看到已经监听0.0.0.0地址了
PS C:\Users\lenovo> netstat -ano | findstr :7078
TCP 0.0.0.0:7078 0.0.0.0:0 LISTENING 184232
TCP 127.0.0.1:7078 127.0.0.1:54840 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54846 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54848 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54852 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54868 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54876 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54878 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54898 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54913 TIME_WAIT 0
TCP 127.0.0.1:7078 127.0.0.1:54943 FIN_WAIT_2 9924
TCP 127.0.0.1:54863 127.0.0.1:7078 TIME_WAIT 0
TCP 127.0.0.1:54870 127.0.0.1:7078 TIME_WAIT 0
TCP 127.0.0.1:54908 127.0.0.1:7078 TIME_WAIT 0
TCP 127.0.0.1:54911 127.0.0.1:7078 TIME_WAIT 0
TCP 127.0.0.1:54920 127.0.0.1:7078 TIME_WAIT 0
TCP 127.0.0.1:54943 127.0.0.1:7078 CLOSE_WAIT 16644
TCP [::]:7078 [::]:0 LISTENING 184232
由于我们的服务器宿主机能和本机windows互通,但是服务器宿主机本身也是可以访问外网的,此时就需要将http请求代理到我们本机的科学上网代理上来,执行如 下命令即可配置:
# 服务器宿主机执行
export HTTPS_PROXY=http://172.16.10.14:7078
export HTTP_PROXY=http://172.16.10.14:7078
此时服务器就可以通过我们的windows代理访问外网了,同时服务器上的docker容器也可以通过服务器宿主机访问外网了,解决ollama在docker容器中无法拉取模型的问题。

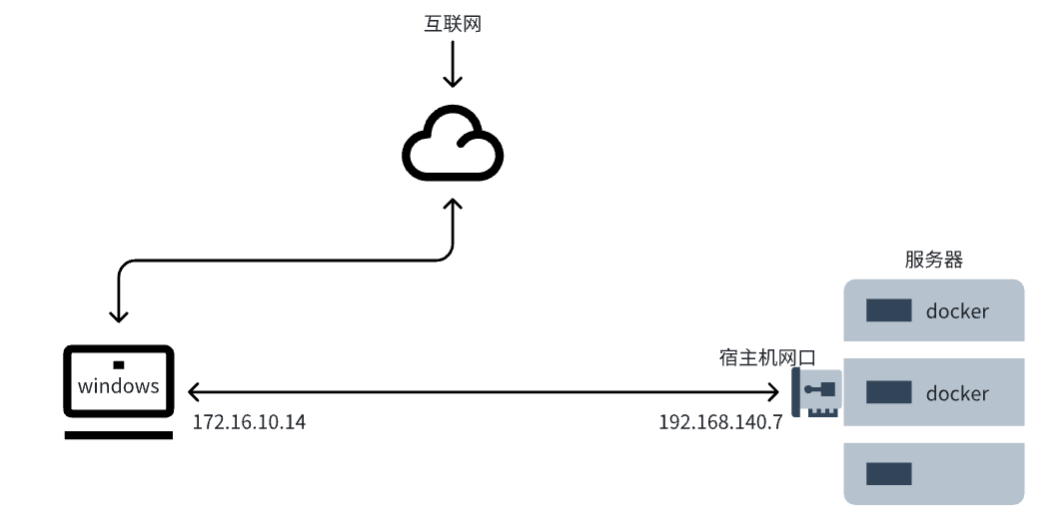
具体的环境如下图所示: