 1874 ' 博客
1874 ' 博客
Spring AI集成本地大模型应用(一)
1. 相关概念
Spring AI 项目旨在简化包含人工智能功能的应用程序的开发,避免不必要的复杂性。Spring AI 解决了人工智能集成的基本挑战:将企业数据和 API 与人工智 能模型连接起来。Spring AI 目前支持处理语言、图像和音频输入输出的模型。
1.1 Prompts
Prompt是语言模型的输入基础,例如Chat-GPT,我们向它输出一段话,并要求它回答,这段话就是一个prompt,你以为这就是全部?prompt实际上可能远不止于 此,在许多的AI模型中,提示的文本不仅仅是一个简单的字符串,一句话。
Chat-GPT的API在一个prompt中有多个文本输出,每个文本输入都被分配了一个角色。
- system:该角色用于高速模型如何表现并设置交互的上下文;
- user:该角色代表的提示通常是用户的输入;
1.2 Token
Token 是 AI 模型工作的基本单元。输入时,模型将单词转换为 token;输出时,再将 token 转换为单词。Token = 金钱,在托管 AI 模型的场景下,费用由 token 数量决定,输入和输出都会计入总 token 数。此外,模型有 token 限制,限制了单次 API 调用可处理的文本量,这通常称为“上下文窗口”。超出该限制 的文本不会被模型处理。
1.3 向AI模型引入你的数据和API
我们知道AI模型的回答内容,都是基于数据训练得到的,如果AI模型没有得到过某些数据,那它怎么基础这些数据来回答我们的相关问题呢?例如GPT3.5/4.0的数据 集只到2021年9月,模型对于之后的信息就不知道了,此时我们有三种方法可以让AI模型结合我们自己的数据:
- Fine Tuning:微调,传统的机器学习方法,通过调整模型内部权重来定制模型。但是这个过程需要专业的机器学习知识和极大的资源消耗,有些模型还不支持。
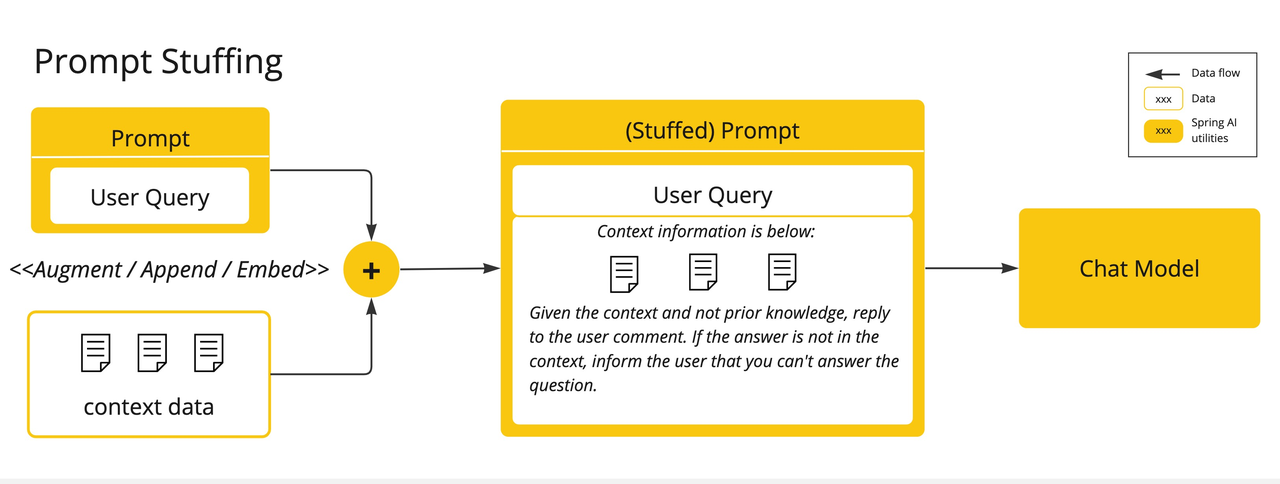
- Prompt Stuffing:提示填充,将我们的数据嵌入到prompt中。Spring AI库中实现了基于stuffing the prompt的方案,也称为检索增强生成(RAG)。
- Tool Calling:该方式允许注册工具(用户自定义的服务),将LLMs与外部系统的API连接。Spring AI也提供的相关的支持,极大简化了工具调用相关的代码。
1.3.1 Retrieval Augmented Generation(RAG)
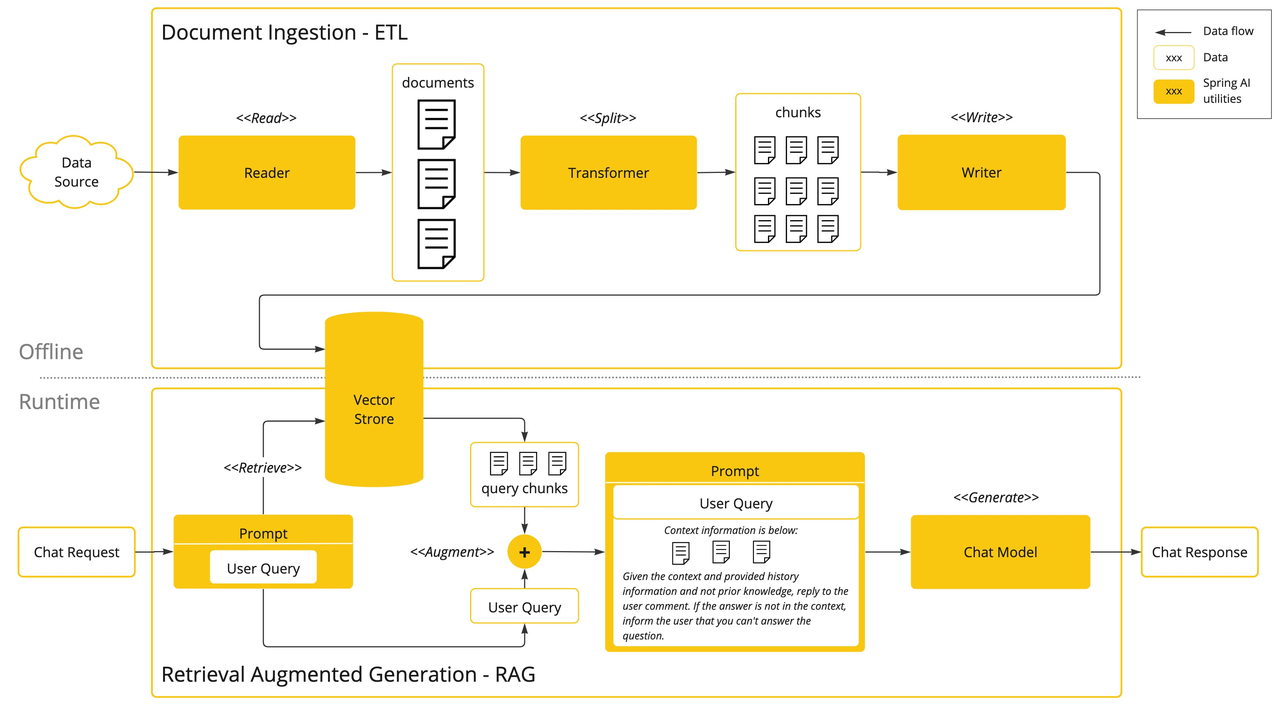
检索增强生成(RAG)技术用于将相关数据纳入提示,以提升 AI 回答的准确性。该方法采用批处理风格的编程模型,作业从文档中读取非结构化数据,转换后写入向 量数据库。从高层看,这是一个 ETL(抽取、转换、加载)流程。向量数据库用于 RAG 技术中的检索环节。
在将非结构化数据加载到向量数据库时,最重要的转换之一是将原始文档拆分为更小的片段。拆分过程有两个关键步骤:
- 在保留内容语义边界的前提下拆分文档。例如,带有段落和表格的文档应避免在段落或表格中间拆分;代码应避免在方法实现中间拆分。
- 进一步将文档片段拆分为仅占 AI 模型 token 限制一小部分的更小片段。
RAG 的下一阶段是处理用户输入。当用户提问时,问题和所有“相似”的文档片段会被放入发送给 AI 模型的提示中。这就是使用向量数据库的原因——它非常擅长查找相似内容。
1.3.2 Tool Calling
工具调用允许你注册自己的服务作为工具,将大语言模型与外部系统 API 连接。这些系统可以为 LLM 提供实时数据并代表其执行数据处理。Spring AI 极大简化
了工具调用相关代码。通过@Tool注解方法并在提示选项中提供,使其对模型可用。也可以在单个提示中定义和引用多个工具。
工具调用主要用于:信息检索和执行操作
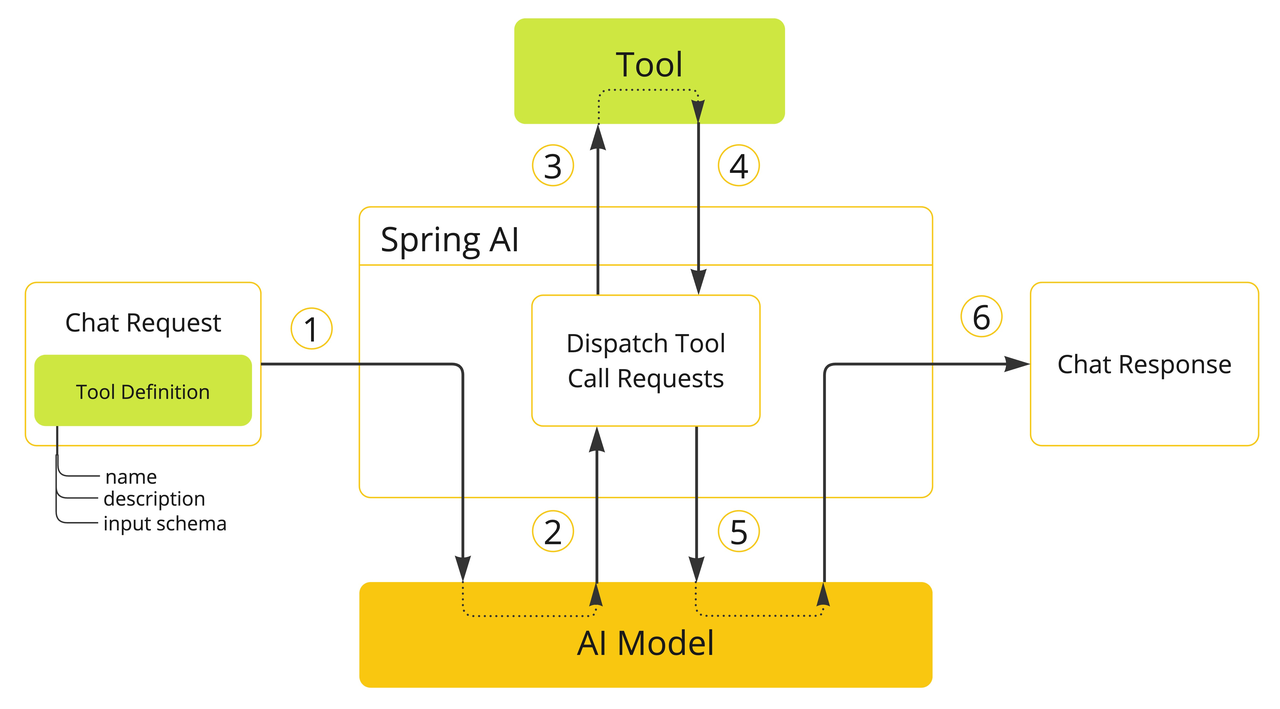 对应图中的步骤解释如下:
对应图中的步骤解释如下:
- 需要让模型可用某个工具时,在聊天请求中包含其定义。每个工具定义包括名称、描述和输入参数的 schema。
- 当模型决定调用工具时,会返回工具名和按 schema 构造的输入参数。
- 应用负责根据工具名识别并执行工具,并传入参数。
- 工具调用结果由应用处理。
- 应用将工具调用结果返回给模型。
- 模型用工具调用结果作为额外上下文生成最终回复。
2. 依赖
Spring AI最近正式发布了1.0.0版本,详情的使用介绍说明见官方文档, Spring AI 官方目前并没有将 1.0.0 的二进制包推送到 Maven 中央仓库,而是选择继续推送到 Spring 自己维护的 Maven 库,需要配置BOM依赖:
<!-- 添加BOM依赖 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
基于前文已经部署好的Ollama模型,我们在项目中添加对应的依赖,使用Spring AI基层Ollama模型,官网提供了相关示例,依赖如下:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- vaadin前端依赖 -->
<dependency>
<groupId>com.vaadin</groupId>
<artifactId>vaadin-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>in.virit</groupId>
<artifactId>viritin</artifactId>
<version>${viritin.version}</version>
</dependency>
<!-- ollama 模型依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
</dependencies>
3. 开发示例
Spring AI会根据配置文件中的配置信息,对大模型进行自动配置并生成对应的实例,我们只需要在业务代码中引入对应的实例即可调用大模型接口进行聊天对话。
server:
port: 9100
spring:
ai:
ollama: # ollama与openai兼容,所以这里可以配置为openai,知识url地址填ollama的地址即可
base-url: http://192.168.140.7:11434
chat:
options:
model: deepseek-r1:7b
编写controller代码后,我们就可以启动项目,然后通过浏览器访问之前部署好的大模型。
@RestController
public class ChatController {
private OllamaChatModel chatModel;
/**
* ChatClient是一个比ChatModel更高层次的封装,集成快速简单
*/
@Resource
private ChatClient chatClient;
/**
* ChatModel是一个底层的抽象,支持底层自定义扩展,如自定义提示词prompt结构等
* @param chatModel 聊天模型
*/
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
/**
* 同步响应
* 使用ChatModel调用
*
* @param message
* @return
*/
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
/**
* 同步响应
* 使用ChatClient进行调用
* 在这个简单的示例中,用户输入设置了用户消息的内容。
* call() 方法向 AI 模型发送请求,content() 方法返回 AI 模型的响应作为 String
* @param message
* @return
*/
@GetMapping("/ai/generate2")
public Map<String,String> generate2(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation",
this.chatClient
.prompt()
.user(message)
.call()
.content());
}
/**
* 流式异步响应,使用SSE(server send event)推送到前端进行实时和前端交互
*
* @param message
* @return
*/
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}
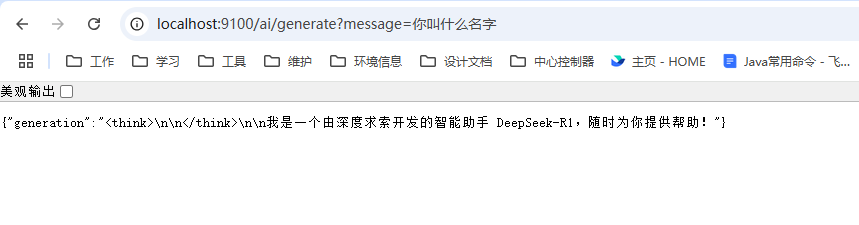
访问效果如下:
 为了更好的进行交互,我们可以用Vaadin实现一个简单的web页面,以进行交互,此处仅贴出
关键代码,详细代码参见Github.
为了更好的进行交互,我们可以用Vaadin实现一个简单的web页面,以进行交互,此处仅贴出
关键代码,详细代码参见Github.
@Route("")
public class ChatView extends VerticalLayout {
private final ChatService chatService;
private VerticalLayout messageList;
public ChatView(ChatService chatService) {
this.chatService = chatService;
initialLayout();
}
private void initialLayout() {
setSizeFull();
String conversationId = chatService.establishChat();
messageList = new VerticalLayout();
messageList.setPadding(true);
messageList.setSpacing(true);
messageList.setWidthFull();
messageList.setHeightFull();
var input = new MessageInput();
input.setWidthFull();
input.addSubmitListener(e -> promptSubmitListener(e, conversationId));
addClassName("centered-content");
add(messageList, input);
}
/**
* 提交信息后的监听器
*
* @param event 提交事件
*/
private void promptSubmitListener(MessageInput.SubmitEvent event, String conversationId) {
var question = event.getValue();
var userMessage = new MarkdownMessage(question, "You", MarkdownMessage.Color.AVATAR_PRESETS[6]);
var aiMessage = new MarkdownMessage("...", "xiaohetao AI", MarkdownMessage.Color.AVATAR_PRESETS[0]);
messageList.add(userMessage, aiMessage);
chatService.chat(conversationId, question)
.map(res -> Optional.of(res.getResult().getOutput().getText()).orElse("抱歉,我无法回答"))
.subscribe(aiMessage::appendMarkdownAsync);
}
}
效果如下所示:
4. 多个聊天模型
springAI默认只能配置一种AI模型,如果我们需要配置多个聊天模型,可以通过如下配置禁用ChatClient.Builder自动配置:
spring.ai.chat.client.enabled=false
应用程序中使用多个聊天模型的几种场景:
- 为不同类型的任务使用不同的模型;
- 当某一个模型不可用时实现回退机制;
- 对不同模型或配置进行A/B测试;
- 根据用户的喜好自行选择模型;
- 组合专业模型(例如一个用于聊天,一个用于图像生成); 应用集成多个聊天模型参见github示例。