 1874 ' 博客
1874 ' 博客
RabbitMQ系列(二)-基本概念和原理
简介
MQ全称为Message Queue, 是一种分布式应用程序的的通信方法,它是消费- 生产者模型的一个典型的代表,生产者向消息队列中生产消息,消费者从消息队列中取出消息, 并将其消费。RabbitMQ便是MQ产品的一个典型代表,它是由Erlang编写的一款基于AMPQ协议 可复用的高性能企业消息系统。当然,消息通信解决方案并不止RabbitMQ一种,诸如ActiveMQ, ZeroMQ,Apache Qpid都提供了相关的解决方案。由于RabbitMQ的可靠性,高性能,高并发, 并且它是处了Apache Pid之外唯一实现了AMPQ标准的代理服务器,使得它相较于其竞争者, 有着更高的普及度,也更加的受大家青睐。从小到创业公司,大到商业巨头,RabbitMQ都有很高 的普及度和忠实用户。
理解消息通信
其实消息通信的整个过程非常的简单,就如上面我们说到的一样,生产者产生消息,
消费者接收到这些消息并将其消费。你的应用程序可以作为生产者,向其他应用程序发送消息,
也可以接收来自其他应用程序发送过来的消息。不过,在此之前,它必须建立一条
信道(channel)。
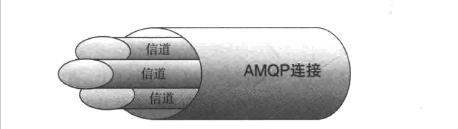
你的应用程序首先需要连接到RabbitMQ,才能发布消息或者是消费。你在应用
程序和RabbitMQ代理服务器之间创建一条TCP连接,一旦连接打开(你通过了认证),应用程序
就可以创建一条AMPQ信道。信道就是建立在“真实的”TCP连接内的虚拟连接。每条信道都会被指派
一个唯一的ID作为标记,这个不需要我们关心,AMPQ库会帮我们记住。不论是发消息,订阅队列
还是接收消息,这些动作都是在信道里面完成的。下图是一个简洁的RabbitMQ通信示意图。
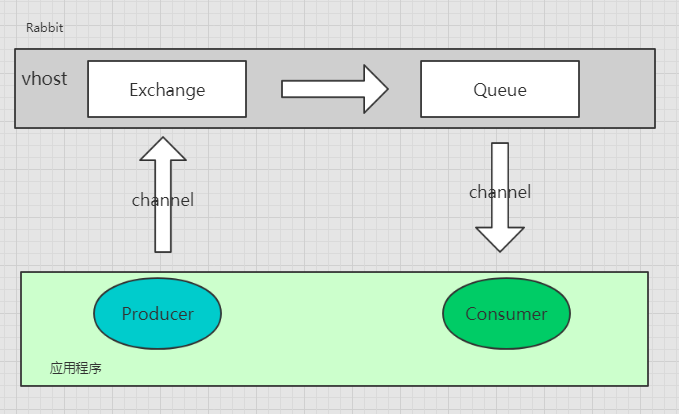
为什么需要信道而不是直接通过TCP连接发送AMPQ命令呢?主要原因在于对操作系统来说,建立和销毁TCP连接是一件非常昂贵的开销。 假设应用程序从队列消费信息,并根据 服务需求合理调度线程,如果我们只进行TCP连接,那么每个线程都需要自行连接到RabbitMQ, 这不仅造成了TCP连接的巨大浪费,而且操作系统每秒的连接数也就只有这么点,很快就会达到 性能的瓶颈。如果我们为所有的线程只使用一条TCP连接以满足性能需求,但又能确保没个线程的私密性 ,就如同每个线程拥有独立的连接一样,其实不是完美?这就是为什么需要信道的原因。
基本概念
Producer&Consumer
其实这个概念并不用我过多的解释,学过操作系统或者是了解设计模式的同学都很
明白,生产者消费者的概念和设计模式中的发布订阅模式类似。一个应用程序负责生产消息,另一个
应用程序则负责接收消息,并对接收到的消息做相应的业务处理,当然,两者的角色是可以互换的
,有时候一个应用程序既对外发送消息,又接收别的应用程序发送过来的消息。我们用下图两个
来表示生产者和消费者。

Exchange
Exchange是RabbitMQ中的消息交换机,生产者产生消息之后,不是直接发送到 队列中,而是首先发送到Exchange。Exchange根据自身的分发策略,将消息发送到与之绑定的 队列中,RabbitMQ支持的Exchange有四种类型,分别是:
-
Direct:直接交换器,类似于单播,Exchange会将生产者传来的消息,根据完全匹配的 routing_key发送到与之绑定的queue上。exchange和queue之间的关联关系就是通过Binding 和routing_key关联起来的,exchange会根据对应的routing_key发送消息到与之绑定的队列上。
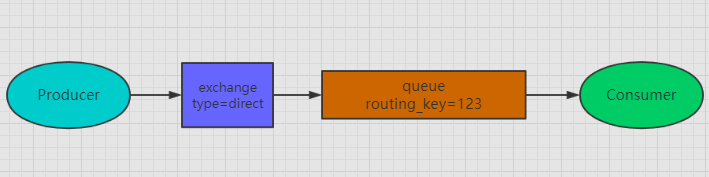
-
Fanout:扇形交换机,工作方式相当于广播,它将消息发送到所有与之绑定的队列上,这种 模式下就没routing_key的概念了,它和发布订阅模式是一样的原理。下图所示,exchange会将 消息路由到与之绑定了的三个队列里。
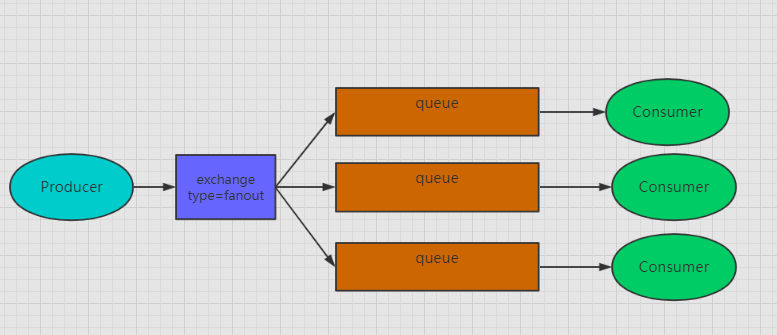
- Topic:上面介绍的两种交换机,一种是严格按照routing_key来路由的,还有一种就是完全
没有路由限制,只要绑定了,那就将消息路由过去。这两种的缺陷是要么太严格,要么又太松散,
实际的业务中,有可能满足不了业务场景需求,所以就出现了topic这种类型的交换机。它的路由
规则相当于表达式匹配。它的routing允许我们以
.进行分割,如”test.user.key”,”test.user.key2”, 同时它还支持一特殊字符”“和”#”用于做模糊匹配,”“用于匹配一个单词,”#”用于匹配多个单词 ,也可以是零个。具体的路由规则如图所示: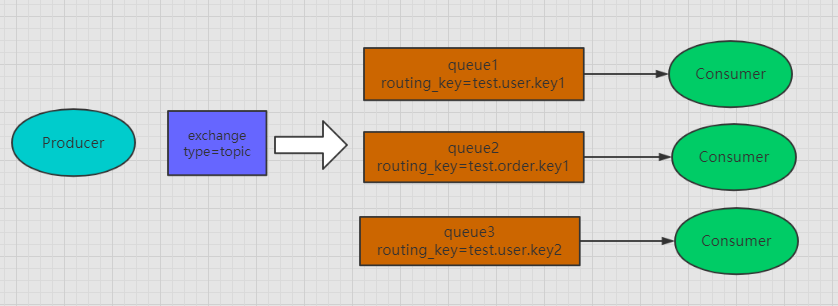 当路由规则是
当路由规则是test.#时会路由到queue1,queue2,queue3上,当路由规则是test.*.key1时 会路由到queue1和queue2上。 - Headers:headers类型的Exchange不依赖于routing key的匹配规则 来路由消息,而是根据发送的消息内容中的headers属性进行匹配。 在绑定Queue与Exchange 时指定一组键值对;当消息发送到Exchange时,RabbitMQ会取到该消息的headers (也是一个键值对的形式),对比其中的键值对是否完全匹配Queue与Exchange绑定时指 定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。由于作者并没有 实际使用过这个类型的exchange,所以这里就不多废话,感兴趣的同学可去研究下。
Queue
queue就是我们上文中提到的消息队列,用于消息的传输。它采用FIFO的处理机制, 对消息具有缓存功能。RabbitMQ为我们提供了队列持久化(durable)的功能,如果我们对声明的队列 不设置持久化的功能,那么我们的队列在服务停止的时候,队列就会被删除。,持久化可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务。由于这里仅为RabbitMQ的简单介绍,所以这里将不讲解RabbitMQ相关的事务。声明队列的时候可以 为队列命名,如果没有则会使用RabbitMQ自带的匿名队列,它是没有持久化的。消费者要接收 消息的时候,只需要监听到相应的队列即可,多个消费者可以监听同一个队列。
Prefetch count
前面说到如果有多个消费者同时订阅同一个Queue中的消息,这时Queue中的消息会被平摊给多个消费者。这时如果每个消息的处理时间不同,就有可能会导致某些消费者一直在忙,而另外一些消费者很快就处理完手头工作并一直空闲的情况。我们可以通过设置prefetchCount来限制Queue每次发送给每个消费者的消息数,比如我们设置prefetchCount=1,则Queue每次给每个消费者发送一条消息,消费者处理完这条消息后Queue会再给该消费者发送一条消息。
Binding
绑定就是上文中提到的,将队列与交换机并绑定在一起,交换机就可以将消息发送到队列中,进行排队处理。
Virtual hosts
在rabbitmq server上可以创建多个虚拟的message broker,又叫做virtual hosts (vhosts)。每一个vhost本质上是一个mini-rabbitmq server,分别管理各自的exchange,和bindings。vhost相当于物理的server,可以为不同app提供边界隔离,使得应用安全的运行在不同的vhost实例上,相互之间不会干扰。producer和consumer连接rabbit server需要指定一个vhost。默认的vhost是/。
总结
至此,RabbitMQ相关的常用基本概念就已经介绍完了,但是 还远远不够,这里只是做了一个简单的介绍,相关的知识大家可以在RbbitMQ实战一书中找到,亦或是从网上其他地方寻找资料学习,文章的末尾我也附带了一本RabbitMQ实战的PDF版。由于这篇文章 写的很仓促,很多东西没有一一仔细解释清楚,等着有空再完善一下吧。下一篇我将会基于Spring搭建一个RabbitMQ的demo实现消息的发送和消费。
参考
简书:https://www.jianshu.com/p/64357bf35808 RabbitMQ实战:https://byeluliangwei.github.io/images/rabbitmq-basic/RabbitMQ实战 高效部署分布式消息队列.pdf